Salesforce Case Intake: Automate Without a Portal Build
Most case intake does not need a full portal. See how QR codes, structured forms, and review-before-create move email and PDF submissions into clean Salesforce cases.

ConvoPro Team
Salesforce AI Workflow Advisors
Featured

How to Automate Salesforce Case Intake Without Overbuilding a Portal
The intake problem that does not look like an intake problem
A field technician finishes a repair and emails a photo and three lines of notes to a service desk. A vendor sends a renewal PDF with the wrong contact. A customer fills out a contact form and writes “broken again” in the description. A regional manager forwards a thread between two engineers and asks for a follow-up case to be created.
By the time a Salesforce case exists for any of these, someone has read the message, opened a case record, retyped the relevant fields, set the priority, assigned the queue, and replied to the sender. Multiply that by twenty or fifty times a week per coordinator and the cost shows up everywhere: slower SLAs, picklist drift, missing required fields, and a queue of cases that started with a typo no one had time to fix.
The instinct, when this gets bad enough, is to build a portal. That instinct is correct in some situations and overbuilt in most. This post explains how to tell the difference, what the lighter alternative looks like, and how to keep Salesforce as the system of record either way.
Why case intake matters more than it should
Cases are downstream of almost everything operational. The intake step is where the data model meets the messy real world, and the quality of that handoff governs the quality of every report, automation, and SLA that runs after it. If intake is loose, every downstream process compensates. Coordinators triage what should have been auto-routed. Managers re-categorize what should have been picklisted on first write. Reports get padded with “Other” because no one captured the right product family at the start.
Industry research on workflow automation consistently identifies workflow redesign as one of the strongest factors associated with operational impact from AI investments. The pain rarely lives in the system of record. It lives in the seam between the system of record and the place the work actually starts. For most Salesforce teams, that seam is case intake.
How teams usually solve case intake today
Three patterns cover most of the field.
The first pattern is the shared inbox. A customer or technician emails a support address. A coordinator reads the message, opens Salesforce, creates a case, copies fields from the email signature, attaches the photo if there is one, sets the priority, and sends an acknowledgement. This is the most common pattern and the most expensive in coordinator time. It also produces the most inconsistent data, because every coordinator interprets free-text differently.
The second pattern is a Salesforce Flow automation triggered by an email-to-case rule or a screen flow on an internal page. This works well when the inputs are already structured and the data model is stable. It works less well when the customer’s free-text description has to be translated into a case type, priority, and routing decision before the record can be useful.
The third pattern is a full portal. A team stands up Experience Cloud, builds branded pages, manages entitlements, and ships authenticated forms for customers, partners, or field technicians. This is the right answer when the team needs a long-lived branded self-service experience with login, role-based content, and broad self-service scope. It is more than most case-intake problems require.
Each of these works in its place. The trouble starts when a team picks a pattern that does not match the actual scope of the workflow.
Where each approach breaks down
The shared inbox breaks down on volume and consistency. Twenty cases a day from twelve different submitters with different writing styles produces twenty different ideas of what “high priority” means. The data quality issue is not the submitter. It is the lack of structure between submission and record.
Flow breaks down when the work starts outside Salesforce. An email-to-case rule can create a case, but it cannot read a photo, infer asset context from a serial number, or ask a clarifying question when the description is too vague. The schema lands clean only if the input was already clean. For most external intake, it is not.
A portal breaks down on cost and time. Standing up Experience Cloud, branding the pages, managing entitlements, and maintaining templates is a multi-month program. For a team that needs structured external intake for one workflow with twenty to a hundred submissions a week, the lift is disproportionate to the value. It is the right tool for the wrong problem when the team is trying to solve case intake specifically.
The result is that many teams either accept the shared-inbox tax or commit to a portal program that takes a quarter to ship before the first case lands.
Practical decision criteria for choosing an intake pattern
Before choosing an intake pattern, the most useful questions are operational rather than philosophical.
The first is frequency. How many cases come through this workflow each week? If the answer is more than twenty, the workflow has earned design attention. If less, automation effort is rarely repaid.
The second is input quality. Does the work start in email, PDF, photo, free-text form, or external submission? If the input is messy and unstructured, no amount of native automation downstream will fix it.
The third is destination. Which Salesforce object and fields must end up populated correctly, and which of those fields are picklisted, required, or governed by validation rules? If those answers are unclear, the workflow needs design before automation.
The fourth is review. Who needs to see the proposed case before it is created? Auto-creation works when the input schema is tight and the writer is trusted. Most external intake is neither.
The fifth is governance. Who controls the connectors, authentication modes, and approval points the intake workflow uses? An admin who cannot see and gate these will not be able to defend the workflow to security.
When the workflow scores high on volume, low on input quality, and clear on destination and review, a workflow layer is usually a lighter and faster answer than either a shared inbox or a portal program.
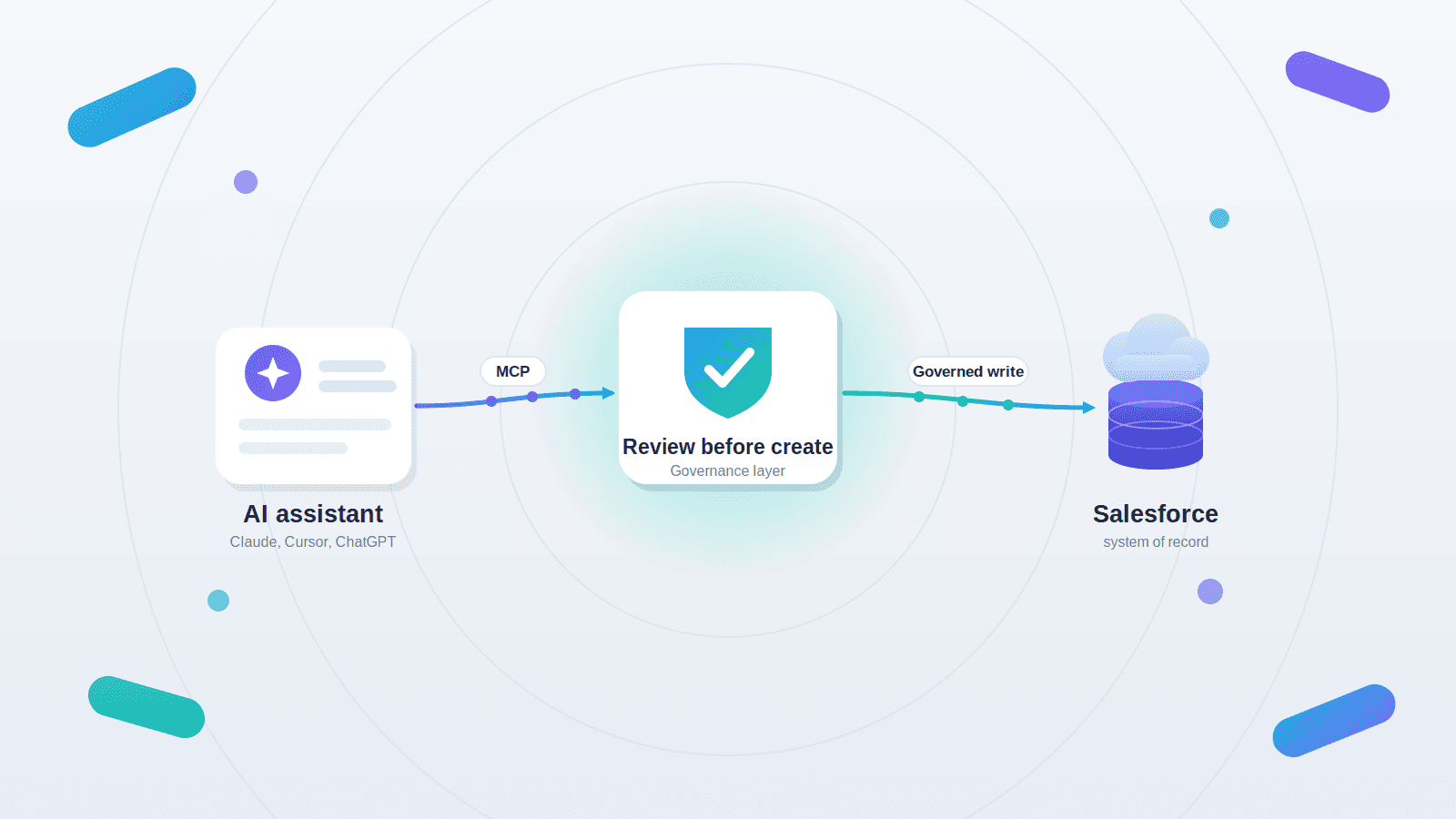
Where an AI workflow layer fits
An AI workflow layer for Salesforce sits between messy real-world inputs and clean Salesforce records. It structures the input against a schema, asks for human review before record creation, writes the result through approved authentication, and notifies any downstream system the workflow requires. Salesforce remains the system of record.
For case intake, the pattern looks like this. The submission begins outside Salesforce, typically through a form, a QR scan, an upload, or an email handoff. The workflow layer reads the input, maps it against the case schema, and proposes a draft case with priority, queue, and required fields filled in. A coordinator or a designated reviewer approves or edits the draft. On approval, the case is written to Salesforce. A summary goes back to the submitter, and any cross-system handoff fires through approved connectors.
Compared to a portal, the design surface is much smaller. Compared to Flow, the upstream complexity, mapping messy input to clean fields, is where the workflow layer actually earns its place. Compared to a shared inbox, the consistency improvement is structural rather than coaching-driven.
ConvoPro is one example of this pattern. ConvoPro Studio handles the Salesforce-aware assistance for summaries, page context, and reusable prompts. ConvoPro Automate handles schema-driven forms, QR-initiated intake, file uploads, and the review-before-create step. Admins gate the connectors and tools. It complements Flow and is a lighter alternative when a full portal is more than the workflow requires.
A concrete example: field asset case intake
Consider a regional service team that supports refrigeration equipment at fifty retail sites. Technicians visit sites and document issues. Today, each visit produces a photo, an asset tag, a location, and a few lines of notes, sent by email or text to a service coordinator. The coordinator reads the message, opens Salesforce, creates a case, types the asset tag, picks the priority based on equipment type, attaches the photo, assigns the queue, and replies. The team handles roughly forty of these per week. Two coordinators spend a meaningful share of their day on intake instead of triage.
With a workflow layer, the same intake runs differently.
The technician scans a QR code printed on the asset. A dynamic form opens with the asset and location already identified from the QR payload.
The technician adds a short note and a photo. The workflow layer reads the note and photo, then drafts a proposed case with priority and queue suggested from the asset type.
The coordinator, or the technician depending on the team’s review preference, sees the proposed case for a quick check. Fields can be edited. Wrong picklists can be corrected before write.
On approval, the case is created in Salesforce through approved authentication, with the photo attached.
An email summary goes to the dispatcher. If the case requires a parts order, a notification fires to the procurement system. The Salesforce case remains the record of truth.
The coordinator role does not disappear. It shifts from re-keying to exception handling. The data quality improves because the schema, not the coordinator’s typing speed, governs the fields. The downstream reports get more trustworthy because the input is consistent. The same pattern repeats for vendor onboarding, HR escalations, IT requests, and departmental intake that today lives in spreadsheets and inboxes.
What to evaluate before going to production
A serious evaluation of any case-intake workflow rests on five questions, in addition to the standard ones any Salesforce AI buyer’s checklist covers.
The first is whether the tool can structure messy input against a Salesforce schema, not just record it. A form is not enough if the inputs still need translation.
The second is whether the review step is configurable. The right review checkpoint differs by team. Some workflows can write directly. Most should not.
The third is which authentication modes are supported when writing to Salesforce. The running-user session is appropriate for some workflows. An integration-user pattern is appropriate for others, especially external submitters.
The fourth is whether admins can gate the connectors, tools, and actions exposed to which workflows. Without that, the tool is not really governed.
The fifth is whether the workflow can be tested in a sandbox or demo org before connecting production data. Testing intake design against representative work is the single most useful pre-production step.
The posture for any of these answers is straightforward. Confirm in writing, not in a demo.
Where this leaves the portal question
A portal is the right answer when the team needs a long-lived branded digital experience with authenticated users, role-based content, and broad self-service scope. For most case-intake problems, that is not the actual scope. The actual scope is structured intake from a defined set of submitters into one Salesforce object with consistent fields. That is the workflow-layer pattern, not the portal pattern.
The good news is the choice is not permanent. A workflow-layer intake can run today, prove value, and inform the portal decision later when the team is ready for a broader experience program. The intake design from the workflow layer often becomes the design specification for the eventual portal forms anyway.
Next step
If your team has a case-intake workflow that runs at least twenty times a week, starts in messy input, and ends in a Salesforce case, the most useful next step is to define the workflow on a single page. Write down the input format, the destination object, the required fields, the review step, and any downstream handoff. With that page in hand, the right tool, native or otherwise, becomes much easier to choose.
You can start a free ConvoPro Studio trial and run the workflow against a demo org, or contact the ConvoPro team to walk through scoping before connecting production data. For broader admin context, the seven ways admins are using AI to reduce manual work is a useful adjacent read.
Frequently asked questions
Is case intake automation the same as email-to-case?
No. Email-to-case takes an email and creates a record. Case intake automation can read messy inputs from many sources, structure them against a schema, propose a draft case, ask for review, and write the result through approved authentication. The output is governed, not just captured.
Does a workflow layer replace Salesforce Flow?
No. Flow is the right tool for native automation that lives inside Salesforce. A workflow layer is more useful when the work starts outside Salesforce or includes messy input that needs structuring before a record can be created. The two are complementary, and most teams use both.
How is this different from Experience Cloud?
Experience Cloud is the right answer when the team needs a branded, authenticated portal with role-based content and broad self-service scope. A workflow layer is lighter and faster when the actual need is structured intake into Salesforce, not a portal program.
What does review-before-create actually mean?
It means the workflow shows the proposed case to a designated reviewer before the record is written to Salesforce. The reviewer can edit fields, correct picklists, or reject the submission. The case is created only on approval. This step is the difference between governed action and freeform automation.
How small can a first workflow be?
One workflow that runs at least twenty times a week, starts in messy input, and ends in clean Salesforce fields is a reasonable first project. Smaller workflows are usually not worth the design effort. Bigger ones should be broken down before any tool is selected.